Reflexiones, desempeño y MLE
En esta entrada hago unas reflexiones sobre mi año en Meta como MLE, sobre cómo sobreviví otro año de evaluación de desempeño y además ganar buena fama dentro del área. También comentaré sobre algunas cosas prácticas en MLE y mi opinión sobre algunos aspectos de la resolución de problemas; y finalmente cómo rechazé una promoción al siguiente nivel (Staff). Y comentaré por qué me cambié de rol nuevamente.
Machine Learning Engineer y reflexiones
A veces digo que algunos SWE (software engineers) resuelven todo con “fulestaahh javaescriihh”, el equivalente en ML es “exyiiboohhh y data pailainee”. Esta “mofa” no la hago por ser un aguafiestas o pesado, pero la hago porque he visto muchos SWE o desarrolladores que piensan que hacer un backend es una API rest, o generar JSON o conectarse a una DB. De la misma manera, por lo que he visto en algunas redes sociales, ocurre un fenómeno parecido en ML: Algun pipeline de datos (en su framework favorito, e.g. airflow), crear el conjunto de entrenamiento, tirar los datos a la juguera y entrenar un modelo XGBoost. O calcular distancias entre vectores; después despilfarrar plata en alguna infraestructura cloud sobredimensionando la solución.
Digamos que vi algo parecido en mi más reciente experiencia. El status quo, era tener un conjunto gigantesco de señales (básicamente features en ML) y luego entrenar un modelo del tipo Gradient Boosting Decision Tree (GBDT). Posteriormente, para una muestra nueva, calcular la probabilidad de la clase objetivo y ejecutar una acción dependiendo de esta probabilidad. Esta arquitectura se muestra en la figura 1.

Fig 1: Arquitectura típica de un modelo de ML para problema de clasificación binaria.
Generalmente, este enfoque funciona bien en la mayoría de los problemas, diría que en el 80% de los problemas funciona. Sin embargo, el problema a resolver tenía una singularidad bastante interesante. Una entidad podía tener una clase en un punto $t=T_1$ pero una clase totalmente distinta en $t=T_2$. Más interesante aún, no se sabe en qué punto la entidad cambió de clase. Por lo tanto, si se intenta formar las muestras $(X_i(t), y_i(t))$, el solapamiento existente podría hacer que $(X_i(t), c_1)$ y $(X_i(t), c_2)$ al mismo tiempo. Una visualización de este problema se muestra en la figura 2.
Qué problema ocurre aquí, es que no se puede saber a qué clase pertence la muestra con las señales $X_i(t)$. Por lo tanto, al entrenar un modelo y evaluar las métricas de desempeño (en este caso era precision y recall), siempre va a entregar resultados que parecen ser positivos (e.g. alta precision y recall) pero que al hacer la evaluación en las predicciones en producción, los resultados van a ser mucho menores.

Fig 2: Problema en que las muestras cambian de etiqueta en un ventana de tiempo.
Por otro lado, también puede ocurrir otro problema. Bajo el supuesto de que las entidades que cambian de etiqueta en un cierto punto, pueden cambiar de etiqueta en un futuro, los modelos se “congelan”. Es decir, predicen siempre la misma clase durante un período de tiempo. Esto es problemático si se considera que al predecir una clase $c_x$, hay un costo monetario en ejecutar alguna acción.
Una posible solución para eliminar los falsos positivos (FP) es considerar el comportamiento previo de la entidad
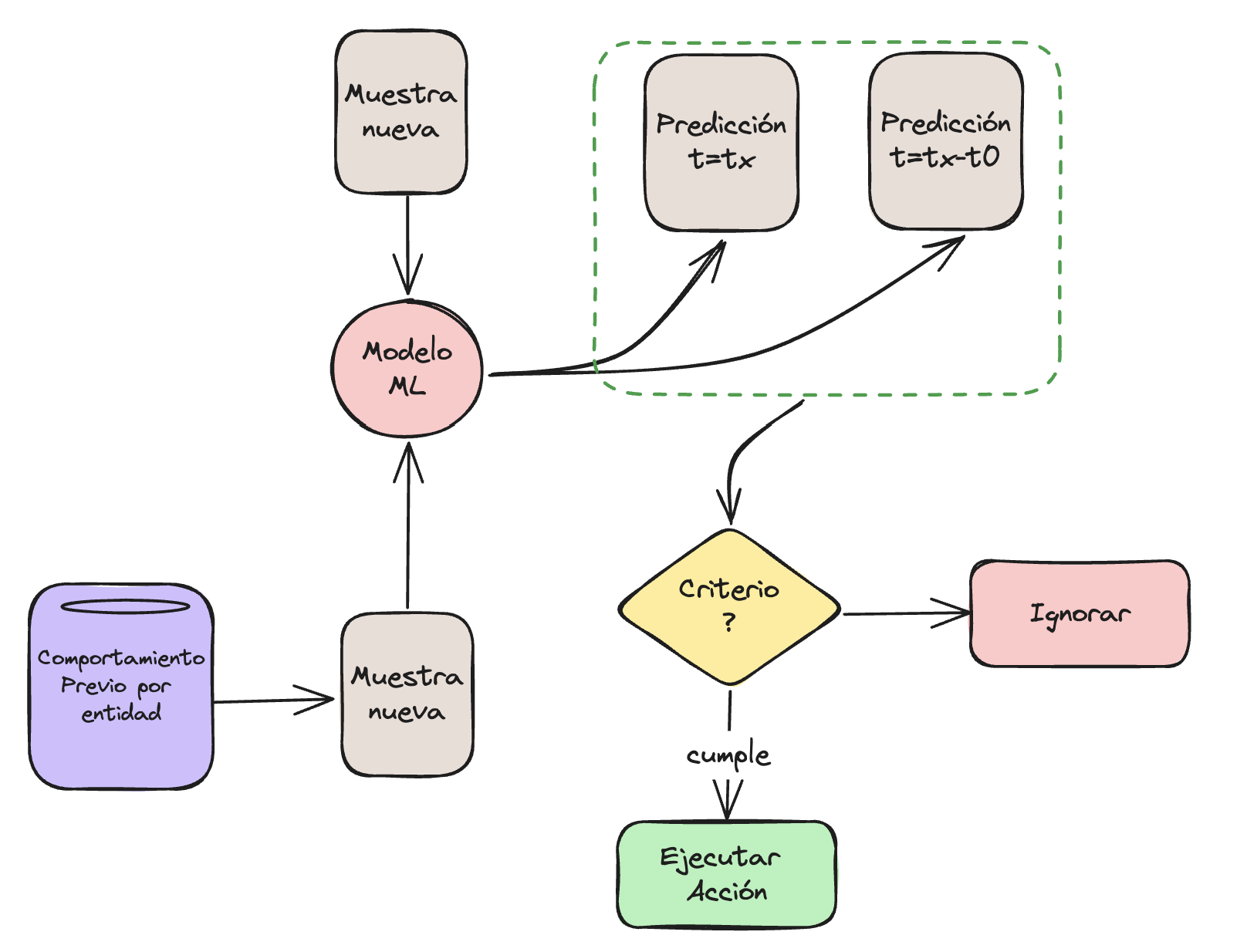
Fig 3: Ejecución del sistema ML considerando comportamiento previo.
Sin embargo, esta entrada de blog no es para hablar de soluciones a problemas específicos. Es más que nada para compartir esta visión de romper el status quo en la resolución de problemas y además tener claro los pro y los contra de cada solución, además de considerar el impacto de la misma, por ejemplo a nivel de negocio.
Tips útiles en mi experiencia
En las siguientes sub-secciones, describo 4 componentes que creo que me ayudaron a ganar buena reputación en mi área. Creo que la retroalimentación que mejor habla de uno, es la que entregan los pares y tiene más impacto que la evaluación que pueda darse uno mismo (esta es mi humilde opinión).
1. Escoger problemas que tengan impacto
Me considero una persona muy técnica en general, y previo a esta experiencia no estaba en mi visión el impacto a nivel de negocio (no digo que no tuviera impacto, digo que no estaba consciente de ello). Generalmente, seguía los requerimientos e implementaba “lo que me pedían”. Aunque mis soluciones técnicas eran destacables, no tenía una noción del impacto de estas soluciones a nivel de negocio. Mirando en perspectiva, imagino que no todos los trabajos que hice tuvieron el mismo nivel de impacto. Me atrevería a decir, que algunas tuvieron un impacto despreciable a nivel de negocio.
Un mentor muy bueno que tuve a inicios de este año, me dijo que si bien yo era muy bueno a nivel técnico y teórico, mi mayor brecha era el resolver problemas que tuvieran impacto. Básicamente, no sólo entregar soluciones elegantes (e.g. con muchas ecuaciones y jerga técnica ), si no que explorar problemas que tuviesen impacto significativo a nivel de negocio. En este contexto, impacto monetario. Al inicio se me hizo complicado y pasé por un periodo de estrés cuestionando mis capacidades, me costó digerir esta crítica, pero al final del día me ayudó bastante. Terminé no sólo creando soluciones “elegantes”, si no que también tuvieron un alto impacto dentro de la organización.
En resumen, hay que tener una forma de medir impacto y cuantificarlo, me topé con varios tipos de problemas:
- Alto riesgo, alta recompensa: Podría tener alto impacto pero arriesgado porque también o podría no funcionar o no tener el impacto esperado
- Complejo técnicamente y no tanto impacto: Soluciones elegantes o crear sistemas complejos pero que al final del día mejoran de manera no significativa alguna métrica de desempeño
- Low hanging fruit: Problemas simples con buen impacto
2. Implementar rápidamente prototipos y pruebas de concepto
Una característica destacable que muchos pares quedaron impresionados, es la cantidad de innovación que realicé en el área. Por ejemplo, implementé una solución al status quo en 6 meses, mejorando en términos de precisión y recall; y consiguiendo habilitar ganancias en el orden de millones de dólares, donde antes, por temas de precisión de los modelos, habría sido inimaginable. El sistema previo había demorado 2 años, y tenía muchas brechas que causaban alto costo humano y fuga de ingresos.
Aquí es donde conectar todo el conocimiento es importante. Esto lo entrega el tener entendimiento del estado del arte, haber sido expuesto a diferentes tipos de problema y la experiencia en ingeniería. Por ejemplo, para resolver el problema de las etiquetas y bajo desempeño, hubo que pensar una solución que consistió en transformar el sistema no lineal, a uno lineal en un punto de operación. Esto lo esbozo en la figura 4.

Fig 4: Ejemplo de simplificación de problema; transformar problema no lineal a uno lineal en un punto de operación cuya vecindad es lineal.
Al tener un punto de operación donde se puede estabilizar el sistema, el problema se pudo reducir a un problema binario donde las etiquetas no cambiaban respecto del tiempo.
3. Realizar experimentos y analizar casos en los que la intuición falla
Uno de los problemas que me topé tenía una componente de NLP (procesamiento de lenguage natural). Actualmente todos son “expertos” en NLP y hablan o de embeddings o sobre Large Language Models. Si bien, se ha democratizado bastante el uso de estos enfoques (APIs, y todos sabemos que usar APIs es bastante simple), hay casos en los que no funcionan. Se me hizo complicado explicarle a las personas de otras áreas y no de ingeniería, por qué usar estos enfoques no iba a funcionar.
Si vamos a lo “teórico”, cada universo puede representarse como un conjunto de axiomas. Los modelos de inteligencia artificial no son diferentes. En esencia existen dos alternativas: Generalización y especialización (ver figura 5). En la generalización nos interesa que el modelo generalice a la mayor cantidad de entradas posible, por ejemplo optimizando el recall. La especialización, por otro lado, intenta remover los resultados incorrectos con el fin de mejorar la precisión al costo de no poder generalizar.

Fig 5: Generalización y especialización.
La solución a la componente de NLP del problema consistió en crear un modelo de lenguaje especializado. Consideré comenzar con una simple variación del modelo de NGramas (post en que explico lo básico de NLP). Básicamente lo que nos interesa es que, dado un lenguaje, queremos predecir la probabilidad de que una cláusula pertenezca a dicho lenguaje. Por lo general, se piensa en el lenguaje que usamos a diario. Sin embargo, uno puede definir un propio lenguaje con sus propias reglas (e.g. un subconjunto del español).
El modelo era simple y funcionaba relativamente bien, excepto que se caía en ciertos casos. Cada caso se analizó por separado, y un patrón que encontré es que el modelo no funcionaba bien en casos en que la diversidad léxica era muy alta. También hubo que analizar otro tipo de características en las entradas problemáticas, como coherencia y otras relaciones entre las componentes de la entrada.
También se probó con modelos más complejos (e.g. embeddings y LLM), pero el costo computacional era demasiado alto y la ganancia en precisión no fue lo suficientemente significativa en comparación al incremento en costo.
En resumen, experimentar, probar distintas soluciones y lograr explicar por qué un enfoque no funciona, son claves para lograr tener éxito en la resolución de problemas y para ganar puntos con el resto de la organización.
4. Escribir código “correcto” e iterar
Tomando el mismo ejemplo de la sección anterior. El modelo de lenguaje implementado tenía algunas brechas, por ejemplo las secuencias textuales estaban muy retringidas y en algunos casos el orden de las palabras no interesaba tanto.
Para solventar el problema anterior, implementé un servicio que basado en índice invertido, Tf-Idf y distancia coseno, calculaba también un puntaje que se utilizaría finalmente para ejecutar una acción. Los resultados de las evaluaciones “offline” eran prometedores, sin embargo cuando se puso en marcha, habían ciertos problemas de precisión;
Para resolver estos problemas, hubo que implementar una componente de “memoria” en el cual se analizaban datos previos y estos se mantenían una caché diaria. Luego, en lugar de considerar un sólo puntaje, se consideró el puntaje del modelo y además el “delta” entre el puntaje nuevo y el máximo puntaje visto para la entidad en la que se realizaría la acción. Esta simple heurística logró un incremento significativo en la precisión sin afectar el recall.
Para lograr derivar las soluciones y mejoras en el sistema, fue importante ser capaz de iterar rápido, descartar soluciones que no tuviesen explicación (e.g. modelos de caja oscura como GBDT o redes neuronales), y además la implementación correcta de estas componentes; es decir que cumplieran ciertos SLA, que no fallaran en producción, y que idealmente no tuviesen bugs. Para ello, escribir tests unitarios y de integración fue clave. También como el correcto análisis de datos y simulaciones del entorno productivo.
El chisme sabroso
Como comenté en la introducción, decidí cambiarme de equipo y desde el otro año estaré trabajando en Pytorch Edge. Hay variadas razones por las cuales tomé esta decisión, pero principalmente es porque me aburrí un poco siendo MLE, y se me abrió una oportunidad de explorar otro problema bastante interesante: Federated Learning. Lo curioso, es que gané tanta fama e implementé un sistema y comencé una visión de la problemática, que de alguna forma me hizo muy importante en el equipo actual. De hecho, me ofrecieron una promoción al siguiente nivel. Sin embargo, consideré que una promoción cada año era mucho y por otro lado, no me siento preparado para estar al siguiente nivel.
Por otro lado, me interesa explorar nuevos problemas, y nuevos roles. Mi siguiente rol será más cercano a infraestructura y estaré implementando ML pero más a bajo nivel (C++ y a nivel de bibliotecas y frameworks de ejecución en hardware).
Conclusiones
- Es importante tener una variada caja de herramientas para la resolución de problemas
- Conectar conocimientos de distintas áreas es útil para encontrar soluciones que el status quo no podría encontrar
- La teoría, la experiencia y el lograr conectar ambos, es relevante desde el punto de vista técnico
- Conectar soluciones con impacto a nivel de negocio es importantísimo. Idealmente aliarse con alguien que tenga una muy clara visión del negocio
- Hacer experimentos para validar o refutar intuiciones debe hacerse con cuidado y siempre considerando los datos a disposición y el método científico