Inteligencia Artificial: Agentes y Conceptos Básicos
Introducción
En estos momentos estoy en Suvarnabhumi Airport, en Bangkok, en el Sakura Lounge de Japan Airlines, esperando para tomar mi vuelo de vuelta a Seattle. ¡Rayos! Las vacaciones pasan rápido. El artículo de hoy será sobre conceptos básicos de inteligencia artificial, en particular “agentes”, ya este término está empezando a sonar bastante con la tendencia de utilizar LLMs en la actualidad. Mi artículo, sin embargo, será un poco más simple e intentará introducir el concepto de manera intuitiva.
Conceptos de IA
Definir qué es la inteligencia artificial puede ser polémico, por lo que no daré una definición directamente en esta ocasión. El libro de Peter Norvig Artificial Intelligence: A modern approach tiene un capítulo introductorio fascinante. El nombre de Inteligencia Artificial para este campo de estudio, fue dado en 1956, aunque anteriormente hubo investigaciones ligadas a lo que desde entonces se conoce como Inteligencia Artificial. Es más, éste campo multidisciplinario toma conocimiento y teoría de: filosofía, lenguaje, psicología, neurociencia, economía, etc (en teoría podríamos estar hablando que la teoría asociada existe desde la época de Aristóteles).
El nombre de IA ha perdurado en el tiempo, pero lo que estudia se asemeja con la racionalidad computacional. La razón de ello, es que en términos de “inteligencia”, la inteligencia artificial considera agentes que toman decisiones de forma racional, idealmente, toma la mejor decisión dada una situación.
Agentes en IA
Primero deberíamos definir qué es un agente, para luego definir qué es un agente inteligente. Un agente, es cualquier ente que pueda percibir su entorno a través de sensores y ejecutar acciones dentro del entorno mediante actuadores, tal como muestra la figura 1. La caja con el signo de interrogación, es qué razonamiento/inteligencia se le provee al agente para que tome acciones dada una percepción del entorno.

Fig 1: Interacción entre agente y entorno en alto nivel.
Cabe destacar que esta noción de agente es una herramienta para analizar sistemas, no es una caracterización que define qué es y qué no es un agente.
Agente Racional
Ahora que definimos un agente, hay que definir qué es un agente racional. Un agente racional es un agente que toma la acción correcta, algunos ejemplos: El controlador de aire acondicionado, esperaríamos que manejara la temperatura acorde a la temperatura configurada (aunque en mi experiencia personal, esto a veces no resulta jeje); una aspiradora roomba, esperaríamos que limpiara satisfactoriamente una habitación dada.
Pero, desde el punto de vista de IA ¿Qué podría definirse como racionalidad? En realidad, lo que es racional depende de cuatro factores:
- La métrica de rendimiento que define un criterio de éxito.
- El conocimiento previo del agente respecto al entorno donde opera.
- Las acciones que el agente puede tomar
- Las percepciones del agente en un momento dado.
¿Omnipotencia?
Aquí también hay que hacer una diferencia entre lo racional y el rendimiento perfecto. Esto es, porque en general, el agente no tiene conocimiento del resultado real de sus acciones, sólo tiene conocimiento del resultado esperado. Si el agente fuese omnipotente (cosa imposible en la práctica), podría maximizar la métrica de rendimiento real, sin embargo, un agente racional busca maximizar la métrica de rendimiento esperada (dado a lo que el agente espera de los resultados de sus acciones). Por ejemplo, si me envían un correo diciendo que gané un millón de dólares, y en efecto no era spam, sin embargo el agente clasificador de correos lo clasificó como SPAM, por lo tanto yo decidí que era SPAM, pero en la realidad no era SPAM, es algo fortuito, que el agente no pudo haber esperado. Otro ejemplo, si no viene ningún auto, el semáforo marca verde, cruzo la calle y me cae la turbina de un avión, no puedo decir que no es racional cruzar en verde; es simplemente mala suerte. Otro ejemplo más actual que se me ocurre, mi instinto arácnido me dice que muchos “modelos predictivos” de algunas empresas no tenían contemplado el COVID-19.
Algunas propiedades de los entornos en que un agente operará son:
- Completamente observable / parcialmente observable (¿Tengo conocimiento total del mundo o sólo parcial?)
- Determinístico / Estocástico (¿El estado siguiente se determina completamente del estado actual?)
- Episódico / secuencial (¿depende mi acción siguiente de mi acción previa?)
- Estático / Dinámico
- Discreto / Continuo
- Un sólo agente / Multiagente
“Inteligencia” en IA
Los tipos de inteligencia en IA se pueden clasificar de acuerdo al razonamiento que hacen sobre el entorno/mundo, como se muestra en la figura 2.

Fig 2: Distintos niveles de “inteligencia” de un agente. Fuente.
Agentes por Reflejo
En este tipo de inteligencia, se encuentran agentes que actúan por reflejo. Consideremos un caso hipótetico de un gato robot, llamémosle RoboCat. A este gato artificial le gusta jugar a seguir un punto generado por un puntero laser.
import numpy as np
class LaserDot:
def __init__(self, pos: int):
self._pos = pos
@property
def pos(self) -> int:
return self._pos
def randomize_pos(self) -> None:
self._pos = np.random.randint(-10, 10)
class RoboCat:
def __init__(self):
self._next_action = None
self._pos = 0
@property
def pos(self) -> int:
return self._pos
def perceive(self, laser_dot: LaserDot):
self._next_action = np.sign(laser_dot.pos - self._pos)
def action(self):
self._pos += self._next_action
Si hacemos una simulación simple, por ejemplo en 100 episodios:
dot = LaserDot(3)
cat = RoboCat()
dot_pos = [3]
cat_pos = [0]
for _ in range(100):
cat.perceive(dot)
cat.action()
dot_pos.append(dot.pos)
cat_pos.append(cat.pos)
if cat.pos == dot.pos:
dot.randomize_pos()

Fig 3: Agente reactivo ejemplo de RoboCat siguiendo un puntero laser.
En la figura 3 se muestra una simulación en 100 episodios del gato robot siguiendo un puntero. El puntero cambia de posición aleatoriamente una vez el gato está en la misma posición que el puntero. Cuando el gato robot percive que el puntero está en otra posición intenta minimizar la distancia entre su posición y la posición del puntero.
En la figura 4 se muestra el controlador en alto nivel de un estanque, donde la variable controlada es la altura del estanque. En este caso, el agente tiene como referencia una altura deseada, y va sensando la altura del estanque en cada instante de tiempo. Si la altura es diferente de la deseada, el controlador la variará para acercarse a la altura deseada.

Fig 4: Ejemplo de un controlador de un estanque.
En general este tipo de inteligencia funciona muy bien para problemas donde se conocen los procesos (modelos matemáticos, físicos, etc), y donde el entorno no es tan cambiante.
Estados
En este tipo de inteligencia, existe la noción de “estados”, en donde el “mundo” o ambiente en que vive el agente se representa por estados, y una acción del agente produce un cambio de estado (que puede determinista o no determinista). Luego, el agente razona sobre acciones futuras y cambios de estado y ejecuta una acción. Este proceso requiere una búsqueda en un espacio de estados, donde la solución, es el camino (conjunto de acciones) que llevan desde un estado inicial hacia un estado objetivo. Cabe destacar, que un en esencia, todo problema puede ser planteado como un problema de búsqueda; Es más, varios algoritmos requieren de alguna forma u otra, resolver problemas de búsqueda. Algunos ejemplos: “Path finding”, soluciones al puzzle de las N piezas, etc.

Fig 5: Ejemplo de árbol de estados para el problema del 8-Puzzle
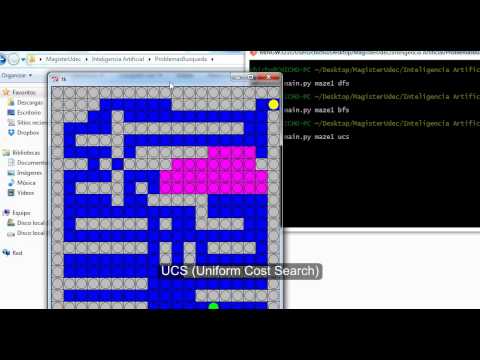
Un ejemplo clásico de problema de búsqueda, es el puzzle de las N-piezas . Este ejemplo es generalmente mostrado en cursos de inteligencia artificial, para mostrar ejemplos de distintos algoritmos de búsqueda: Depth-First Search, Breadth first search, Iterative Deepening Search, Uniform Cost Search, A* Search, Iterative Deepening A* search, inserte cualquier otro algoritmo de búsqueda que tenga alguna optimización en memoria o en reducción del espacio de búsqueda. En la figura 5, se muestra como se va armando el árbol de búsqueda. Por otro lado, existen dos tipos de búsqueda, la búsqueda no informada y la informada. La búsqueda no informada es básicamente hacer fuerza bruta y recorrer todo el árbol de búsqueda hasta encontrar la solución (estado objetivo). Por otro lado, está la búsqueda informada, en la cual se proporciona información respecto a qué tan cerca (o lejos) el estado actual se encuentra del estado objetivo. Generalmente estas funciones son de la forma $h(s) = n$, donde $s$ es un estado y $n$ es una estimación del costo que existe para ir del estado s al estado objetivo. Dependiendo de qué tan buena sea la heurística, se puede llegar más rápido al estado objetivo (expandir menos nodos). En general existen dos propiedades deseables en las heurísticas, admisibilidad y consistencia. La consistencia es sólo importante si se explora el espacio de estados como una búsqueda en grafo (no repetir estados, manteniendo una agenda de estados visitados).
En el siguiente enlace pueden ver un demo de búsqueda por grafos para el puzzle de las 8 piezas: Demo 8-puzzle A*
En general, para implementar estos algoritmos se requiere representar los estados, por ejemplo:
abstract class State {
prev: State
action: string;
constructor (prev: State, action: string) {
this.prev = prev;
this.action = action;
}
abstract equals(otherState: State): boolean;
abstract hash(): string;
}
abstract class SearchProblem {
abstract getStartState() : State;
abstract isGoalState(state: State) : boolean;
abstract getSuccessors(state: State) : State[];
abstract getCostOfAction(state: State) : number;
}
El siguiente snippet muestra una implementación simple del algoritmo A* para búsqueda en grafos:
function aStar(problem: SearchProblem, heuristic: (state: State) => number ) {
let frontier = new BinaryHeap<State>(
(state: State) => heuristic(state) + problem.getCostOfAction(state));
frontier.push(problem.getStartState());
let explored = new StateSet();
while (frontier.size() !== 0) {
let state: State = frontier.pop();
explored.add(state);
if (problem.isGoalState(state)) {
let curr: State = state;
let path = [];
while (curr.prev !== null) {
path.unshift(curr.action);
curr = curr.prev;
}
return path;
}
let neighbors: State[] = problem.getSuccessors(state);
neighbors.forEach( (neighbor) => {
if (!explored.has(neighbor)) {
frontier.push(neighbor);
}
});
}
return [];
}
Nota aparte: Para resolver instancias de puzzle más grande, no es suficiente usar A* (ya que la RAM es limitada y el espacio de búsqueda crece exponencialmente). Para resolver instancias más grandes del (N^2 - 1) puzzle, siempre se puede aplicar algún algoritmo, como en este paper (Combinación de algoritmo greedy + algoritmo de búsqueda)
Solo por completitud, en el siguiente video hay una demo de algunos de los algoritmos de búsqueda clásicos, para el problema de “path finding”, que probablemente hice hace mucho tiempo.
Otro ejemplo de problema de búsqueda (con teoría de juegos aplicadas), es diseñar una IA que juegue el 2048 game. En el siguiente video se muestra un ejemplo (usa un algoritmo llamado MiniMax, basado en juegos “Zero Sum” de teoría de juegos), y el agente se pone en el peor caso (es decir siempre considera la peor situación, lo que a veces lo lleva a hacer movidas muy conservadoras):

Variables
Este tipo de problemas utilizan representaciones un poco más avanzadas del mundo y del entorno, en forma de variables. Algunos ejemplos: redes Bayesianas, problemas de satisfacción de restricciones, etc. (en teoría Machine Learning estaría un poco más adelante en la “línea de inteligencia” mostrada anteriormente).
Un ejemplo clásico es resolver un Sudoku:
- No se pueden repetir números en las filas.
- No se pueden repetir números en las columnas.
- No se pueden repetir números en cada cuadrado del sudoku.
Si consideramos que cada celda del Sudoku es una variable, tenemos 9x9 variables. Por ejemplo si a cada fila le asignamos una letra y a cada columna un valor, podríamos definir las variables como:
$$\{A, B, C, D, E, F, G, H, I\} \times \{1, 2, 3, 4, 5, 6, 7, 8, 9\}$$
En este caso, el dominio de cada variable será el conjunto $\{1, 2, 3, 4, 5, 6, 7, 8, 9\}$ ya que cada celda puede tomar alguno de dichos valores.
En el siguiente código, hay una humilde implementación del algoritmo AC3 para problema de satisfacción de restricciones.
Por ejemplo podemos representar el Sudoku como un problema de satisfacción de restricciones, siguiendo las restricciones descritas:
class Sudoku(ConstraintProgrammingProblem):
def __init__(self, sudoku):
self._variables = {}
self._domains = {}
self._arcs = []
self._constraints = {}
self._unassigned_variables = []
self._alldifferent = []
rows = "ABCDEFGHI"
cols = "123456789"
i = 0
for row in rows:
for col in cols:
self._variables[row + col] = (
None if sudoku[i] == "0" else int(sudoku[i])
)
self._domains[row + col] = (
list(range(1, 10)) if sudoku[i] == "0" else [int(sudoku[i])]
)
if sudoku[i] == "0":
self._unassigned_variables.append(row + col)
i += 1
for i in rows:
tmp = []
for j in cols:
tmp.append(i + j)
for k in cols:
if j != k:
arc = frozenset((i + j, i + k))
if arc not in self._arcs:
self._arcs.append(arc)
self._constraints[arc] = [
'variable["%s"] != variable["%s"]' % (i + j, i + k)
]
self._alldifferent.append(tmp)
for i in cols:
tmp = []
for j in rows:
tmp.append(j + i)
for k in rows:
if j != k:
arc = frozenset((j + i, k + i))
if arc not in self._arcs:
self._arcs.append(arc)
self._constraints[arc] = [
'variable["%s"] != variable["%s"]' % (j + i, k + i)
]
self._alldifferent.append(tmp)
for i in range(3):
for j in range(3):
tmp = [
row + col
for row in rows[i * 3 : i * 3 + 3]
for col in cols[j * 3 : j * 3 + 3]
]
self._alldifferent.append(tmp)
for r in tmp:
for c in tmp:
if r != c:
arc = frozenset((r, c))
if arc not in self._arcs:
self._arcs.append(arc)
self._constraints[arc] = [
'variable["%s"] != variable["%s"]' % (r, c)
]
def arcs(self):
return list(self._arcs)
def constraints(self, Xi, Xj):
return self._constraints[frozenset((Xi, Xj))]
def neighbors(self, X, removable_neighbor=None):
neighbors = []
for arc in self._arcs:
X1, X2 = arc
if X1 == X:
if not removable_neighbor is None:
if removable_neighbor != X2:
neighbors.append(X2)
else:
neighbors.append(X2)
elif X2 == X:
if not removable_neighbor is None:
if removable_neighbor != X1:
neighbors.append(X1)
else:
neighbors.append(X1)
return neighbors
def domain(self, Xi):
return self._domains[Xi]
def remove_from_domain(self, x, Xi):
self._domains[Xi].remove(x)
def unassigned_variables(self):
return list(self._unassigned_variables)
def assign_variable(self, X, value, remove=False):
"""
Asigna un valor a la variable X
"""
self._variables[X] = value
if remove:
self._unassigned_variables.remove(X)
def check_consistency(self):
"""
Chequea que dada una asignación de variables, todas las reglas del
Sudoku se satisfacen
"""
for variables in self._alldifferent:
for i in range(len(variables)):
X = variables[i]
for j in range(i + 1, len(variables)):
Y = variables[j]
are_assigned = (
not self._variables[X] is None
and not self._variables[Y] is None
)
if are_assigned and self._variables[X] == self._variables[Y]:
return False
return True
def __str__(self):
"""
Imprime en pantalla el Sudoku en su estado actual dadas las variables
asignadas.
"""
s = ""
line = "-------------------------------------\n"
s += line
for row in "ABCDEFGHI":
s += "|"
for col in "123456789":
if not self._variables[row + col] is None:
s += ("%3d" % self._variables[row + col]) + "|"
else:
s += ("%3s" % " ") + "|"
s += "\n" + line
return s
Y luego ejecutar el algoritmo AC3:
example = "000102900"
example += "000090301"
example += "000008006"
example += "000030000"
example += "062000000"
example += "079016000"
example += "008060007"
example += "004000190"
example += "000004020"
cp = Sudoku(example)
print(cp)
AC3(cp)
sol = backtracking_search(cp)
for X in sol:
cp.assign_variable(X, sol[X])
Sudoku inicial:
-------------------------------------
| | | | 1| | 2| 9| | |
-------------------------------------
| | | | | 9| | 3| | 1|
-------------------------------------
| | | | | | 8| | | 6|
-------------------------------------
| | | | | 3| | | | |
-------------------------------------
| | 6| 2| | | | | | |
-------------------------------------
| | 7| 9| | 1| 6| | | |
-------------------------------------
| | | 8| | 6| | | | 7|
-------------------------------------
| | | 4| | | | 1| 9| |
-------------------------------------
| | | | | | 4| | 2| |
-------------------------------------
Sudoku final:
-------------------------------------
| 8| 3| 6| 1| 5| 2| 9| 7| 4|
-------------------------------------
| 2| 4| 5| 6| 9| 7| 3| 8| 1|
-------------------------------------
| 1| 9| 7| 3| 4| 8| 2| 5| 6|
-------------------------------------
| 4| 8| 1| 2| 3| 5| 7| 6| 9|
-------------------------------------
| 5| 6| 2| 4| 7| 9| 8| 1| 3|
-------------------------------------
| 3| 7| 9| 8| 1| 6| 5| 4| 2|
-------------------------------------
| 9| 2| 8| 5| 6| 1| 4| 3| 7|
-------------------------------------
| 6| 5| 4| 7| 2| 3| 1| 9| 8|
-------------------------------------
| 7| 1| 3| 9| 8| 4| 6| 2| 5|
-------------------------------------
En este caso, consideramos ninguna función de costo a optimizar. Generalmente queremos minimizar/maximizar una función y a la vez satisfacer las restricciones. Estos problemas de optimización son un mundo, y para que funcionen bien los algoritmos, el problema debe ser modelado de forma correcta, y algunas restricciones pueden podar el árbol de búsqueda (ej. dual de una restricción) de manera de hacer que encontrar una solución sea factible (En el ejemplo del Sudoku, IA toma prestado conocimiento del campo de la optimización, para crear un agente “inteligente” que resuelva sudokus).
Lógica
En este punto me extenderé un poco más, ya que es un área bastante interesante, además, implementar un agente lógico es todo un desafío.
Los agentes lógicos siguen una cadena de razonamiento en base a símbolos y representan el conocimiento en una base de conocimiento, de la que se obtienen inferencias en relación a un determinado hecho. El clásico ejemplo: Todo hombre es mortal; Sócrates es Hombre; Por lo tanto Sócrates es mortal. Este ejemplo sigue una cadena lógica de razonamiento, la gran pregunta es cómo representar este conocimiento de manera que automáticamente un agente sea capaz de realizar inferencias y luego tomar acción. Para hacerlo más entretenido, tomemos el clásico ejemplo del mundo del Wumpus:

Fig 6: Mundo del Wumpus.
De momento consideremos lo siguiente:
- El mundo es una grilla de 4x4
- Los cuadrados adyacentes al Wumpus tienen hedor del wumpus y en los cuadrados adyacentes a los precipicios, se puede percibir una brisa.
- Se puede percibir un brillo si en la habitación se encuentra el oro (aquí es donde nuestro agente gana el juego)
Métricas de rendimiento:
- Si el agente toma el oro +1000 puntos
- Si el agente muere (se cae a un precipicio o es comido por el Wumpus) -1000 puntos
- -1 punto por cada acción
- El juego termina cuando el agente toma el oro o muere.
Entorno:
- Grilla de 4x4
- El agente empieza en la posición
[1, 1] - Las ubicaciones del Wumpus y del Oro se escogen aleatoriamente de una distribución uniforme de todos los cuadrados excepto del
[1, 1] - Cada cuadrado (que no sea el
[1, 1]) tiene una probabilidad de 0.2 de ser un precipicio.
Actuadores:
- Girar izquierda, girar derecha, avanzar, recoger
Sensores:
- Hedor, brisa, brillo
Propiedades del mundo:
- Parcialmente observable
- Estático
- Discreto
- Un sólo agente
- Determinista
- Secuencial
Primero, debemos modelar la base de conocimiento que tendrá el agente. Ello se puede lograr por ejemplo, con lógica proposicional (aquí recuerdo las clases de álgebra de primer año y me empiezan a hacer sentido). De hecho como ejemplo tomemos la figura mostrada anteriormente. De las reglas del mundo del Wumpus, el agente debería saber:
- $B_{11} \leftrightarrow \left( P_{12} \lor P_{21}\right)$
- $\neg B_{11}$
En mi biblioteca opensource PyLogic implemento una API para lógica proposicional y para cláusulas de Horn (sub-conjunto de la lógica de primer orden).
Entonces, el agente, para decidir su siguiente acción, puede preguntarse: ¿Es [1, 2] seguro, o $\neg P_{12}$? Consideremos la siguiente tabla de verdad:

Fig 7: Tabla de verdad para ejemplo de consecuencia lógica para determinar precipicio.
Como se ilustra en la tabla de verdad, en todo modelo en que la base de conocimiento es verdad (asignación de variables lógicas) se satisface que $\neg P_{12}$, es decir que $\neg P_{12}$ es una consecuencia lógica de $\neg B_{11} \land \left(B_{11} \leftrightarrow \left(P_{12} \lor P_{21} \right)\right)$ , o, el hecho de que no haya brisa en la habitación [1, 1], significa que las habitaciones [1, 2], [2, 1] son seguras (no hay precipicio). Ahora, podemos ver un inconveniente de hacer inferencias con tablas de verdad, y es que, crece exponencialmente con el número de símbolos y el número de cláusulas. Luego, para problemas no de juguete, no sería factible construir la tabla de verdad. Por otro lado vemos también que al construir la tabla de verdad, entre medio se construyen muchas asignaciones innecesarias, por lo que debe haber alguna forma más inteligente de llevar a cabo la “búsqueda” de satisfacibilidad. Sin embargo, en esta búsqueda debemos también considerar la correctitud y la completitud. Como dato extra, los problemas de satisfacibilidad Booleana son NP 😊.
Para automatizar un algoritmo de inferencia lógica, es ideal que las cláusulas se puedan escribir de alguna forma canónica. Por suerte, dicha forma existe y se conoce como Forma Normal Conjuntiva (del inglés CNF, conjunctive normal form). De hecho, cualquier cláusula (por ahora en lógica proposicional) se puede escribir como una conjunción de disyunciones. Tomemos como ejemplo la cláusula $\left(B_{11} \leftrightarrow \left(P_{12} \lor P_{21} \right)\right)$:
- $\left(B_{11} \rightarrow \left(P_{12} \lor P_{21}\right)\right) \land \left(\left(P_{12} \lor P_{21}\right) \rightarrow B_{11} \right)$
Usando $A \rightarrow B \iff \neg A \lor B$ tenemos que:
- $\left(\neg B_{11} \lor P_{12} \lor P_{21} \right) \land \left((\neg P_{12} \land \neg P_{21}) \lor B_{11}\right)$
Distribuyendo:
- $\left(\neg B_{11} \lor P_{12} \lor P_{21} \right) \land \left(B_{11} \lor \neg P_{12}\right) \land \left(B_{11} \lor \neg P_{21}\right)$
De esta forma obtenemos 3 cláusulas que podemos insertar en nuestra base de conocimiento canonicalizada. Como observación, Modus Ponens es si tengo $P$ y $P \rightarrow Q$, entonces también tengo $Q$. En CNF, tendríamos dos cláusulas $P \land \left(\neg P \lor Q\right)$, luego distribuyendo y resolviendo se llega a $\left(P \lor \neg P\right) \land \left(P \lor Q\right)$, y como $P \lor \neg P$ es siempre verdadero, entonces sólo nos quedamos con $\left(P \lor Q\right)$. Esta “regla” se conoce como regla de resolución, y puede ser utilizada para realizar una demostración por contradicción (reducción al absurdo). Volviendo al ejemplo anterior, para demostrar que [1, 2] es seguro (no hay precipicio), podemos seguir la siguiente cadena de razonamiento:
- Supongamos que hay un precipicio $P_{12}$.
- Haciendo resolución entre $P_{12}$ y $\neg P_{12} \lor B_{11}$, llegamos a $B_{11}$.
- Sin embargo, tenemos en la base de conocimiento que $\neg B_{11}$ es cierto, lo que es contradictorio.
- Por lo tanto, podemos concluir que la premisa $P_{12}$ no puede ser verdadera y por lo tanto es seguro visitar la posición
[1, 2].

Fig 8: Algoritmo de resolución en lógica proposicional.
El algoritmo de resolución está implementado en pylogic y sigue una idea similar al pseudo-código excepto que tiene algunas heurísticas extra para hacer el algoritmo más eficiente. Cabe destacar que el espacio de búsqueda también crece exponencialmente con la cantidad de símbolos y cláusulas.
El lector astuto podrá notar que para la representación del mundo tuvimos que usar una cláusula para cada precipicio, hedor y brisa. Sin embargo, podemos obtener una representación más compacta. Para desarrollar esta intuición, consideremos el siguiente argumento, que es un silogismo (Aristóteles) clásico:
$$ \begin{array} {c} \text{Todo hombre es mortal} \\ \text{Sócrates es hombre} \\ \hline \text{Sócrates es mortal} \end{array} $$
Cabe destacar que matemáticamente, estos axiomas se pueden fórmular con Lógica de Primer Orden:
$$ \begin{array} {c} \forall x (Hombre(x) \rightarrow Mortal(x)) \\ Hombre(s) \\ \hline Mortal(s) \end{array} $$
En el caso del problema del Wumpus, por ejemplo para un precipicio, podriamos representarlo como $P(a, b)$ donde $a$ y $b$ son objetos en este universo, que representan coordenadas en el mundo del Wumpus.
Por otro lado, cabe destacar que existe un subconjunto de la lógica en el cual consideramos sólo cierto tipo de cláusulas. Por ejemplo, las cláusulas de Horn son disyunciones de literales en donde a lo más un literal está sin negación, por ejemplo: $\neg A \lor \neg B \lor C$ es una cláusula de Horn, esta puede representarse como $A \land B \rightarrow C$, es decir una conjunción de antecedentes y un consecuente. Esto permite implementar algoritmos eficientes para ciertos problemas de satisfacibilidad.
Consideremos el siguiente problema. Tenemos un mapa de Australia con las siguientes regiones:
- WA: Western Australia
- NT: Northern Territory
- SA: South Australia
- Q: Queensland
- NSW: New South Wales
- V: Victoria

Fig 9: Problema de coloreado de mapas (Australia).
Supongamos que queremos colorear el mapa de tal manera que dos regiones adyacentes no sean del mismo color. Podemos representar el problema los siguientes axiomas en modo de cláusulas de Horn:
$$ \begin{array} { rr} \quad Diff(wa, nt) \land Diff(wa, sa) \land \\ Diff(nt, q) \land Diff(nt, sa) \land \\ Diff(q, nsw) \land Diff(q, sa) \land \\ Diff(nsw, v) \land Diff(nsw, a) \land \\ Diff(v, sa) \Rightarrow Coloreable() \\ Diff(Red, Blue) \quad Diff(Red, Green) \\ Diff(Blue, Red) \quad Diff(Blue, Green) \\ Diff(Green, Red) \quad Diff(Green, Blue) \end{array} $$
Utilizando mi biblioteca pylogic:
from pylogic.fol import (
HornClauseFOL,
Predicate,
Term,
TermType,
fol_bc_ask,
Substitution,
)
wa = Term("wa", TermType.VARIABLE)
sa = Term("sa", TermType.VARIABLE)
nt = Term("nt", TermType.VARIABLE)
q = Term("q", TermType.VARIABLE)
nsw = Term("nsw", TermType.VARIABLE)
v = Term("v", TermType.VARIABLE)
t = Term("t", TermType.VARIABLE)
map = HornClauseFOL(
[
Predicate("Diff", [wa, nt]),
Predicate("Diff", [wa, sa]),
Predicate("Diff", [nt, q]),
Predicate("Diff", [nt, sa]),
Predicate("Diff", [q, nsw]),
Predicate("Diff", [q, sa]),
Predicate("Diff", [nsw, v]),
Predicate("Diff", [nsw, sa]),
Predicate("Diff", [v, sa]),
],
Predicate("Colorable", []),
)
red = Term("Red", TermType.CONSTANT)
blue = Term("Blue", TermType.CONSTANT)
green = Term("Green", TermType.CONSTANT)
p1 = HornClauseFOL(
[],
Predicate("Diff", [red, blue]),
)
p2 = HornClauseFOL(
[],
Predicate("Diff", [red, green]),
)
p3 = HornClauseFOL(
[],
Predicate("Diff", [green, red]),
)
p4 = HornClauseFOL(
[],
Predicate("Diff", [green, blue]),
)
p5 = HornClauseFOL(
[],
Predicate("Diff", [blue, red]),
)
p6 = HornClauseFOL([], Predicate("Diff", [blue, green]))
kb = [map, p1, p2, p3, p4, p5, p6]
goal = Predicate("Colorable", [])
answers = fol_bc_ask(kb, [goal], Substitution({}))
for answer in answers:
for k, v in answer.substitution_values.items():
print(k, v)
print("=" * 7)
La cual entrega múltiples soluciones, por ejemplo:

Fig 10: Soluciones entregadas por PyLogic para el problema de coloreado de mapas.
Un poco más sobre problemas de búsqueda
Gran parte de la IA, puede reducirse a un problema de búsqueda.
- En machine learning estamos buscando “el mejor modelo” en base a algún criterio (por ejemplo ajuste de datos)
- En problemas de estados, estamos buscando “el mejor camino” para llegar de un estado inicial a un estado objetivo
- En lógica dada una cláusula y una base de conocimiento estamos buscando si esta cláusula se puede satisfacer dado el conocimiento embebido en la base.
- En problemas de satisfacción de restricciones, estamos buscando la solución que cumpla todas las restricciones y que minimice o maximice una función objetivo.
El cómo se hace la búsqueda es donde uno tiene que poner cerebro a resolver el problema.
Ejemplo de Estimación de Parámetros
Supongamos que tenemos los siguientes datos:
t = [0., 0.11111111, 0.22222222, 0.33333333, 0.44444444, 0.55555556, 0.66666667, 0.77777778, 0.88888889, 1.]v = [100.96510126, 67.78222915, 48.48101823, 24.98947315, 18.23139621, 12.91163503, 5.18434069, 7.19801177, 4.63123254, 1.91433441]
Queremos encontrar un modelo que ajuste dichos datos. Supongamos que estudiamos el modelo físico:
$$v(t) = v_0 \cdot e^{-\frac{t}{\tau}}$$
En este caso podemos transformar el problema a uno lineal en sus parámetros ($v_0$ y $\tau$):
- $log\left(v\left(t\right)\right) = log\left(v_0\right) + log\left(e^{-\frac{t}{\tau}}\right)$
- $log\left(v\left(t\right)\right) = a - b\cdot t$
Luego aplicar mínimos cuadrados para encontrar $a$ y $b$ y re-transformar a los parámetros originales:
V0 = 100
tau = 0.25
t_truth = np.linspace(0, 1)
t = np.array(
[
0.0,
0.11111111,
0.22222222,
0.33333333,
0.44444444,
0.55555556,
0.66666667,
0.77777778,
0.88888889,
1.0,
]
)
v = np.array(
[
100.96510126,
67.78222915,
48.48101823,
24.98947315,
18.23139621,
12.91163503,
5.18434069,
7.19801177,
4.63123254,
1.91433441,
]
)
A = np.array([np.ones(t.shape), -t])
b = np.log(v)
sol, _, _, _ = np.linalg.lstsq(A.T, b, rcond=None)
V0_approx = np.exp(sol[0])
tau_approx = 1 / sol[1]
print(f"V0 = {V0}; tau = {tau}")
V_truth = V0 * np.exp(-t_truth / tau)
V_approx = V0_approx * np.exp(-t_truth / tau_approx)
plt.plot(t_truth, V_truth, "-b")
plt.plot(t, v, "*r")
plt.plot(t_truth, V_approx, "-g")
plt.legend(("Función Original", "Medidas con ruido", "Solución encontrada"))
La salida del programa previo es:
V0 = 100; tau = 0.25
V0_approx = 99.8009989146457; tau_approx = 0.2654186277602548

Fig 11: Ejemplo de búsqueda de parámetros por mínimos cuadrados.
El resultado indica que podemos estimar los parámetros y dependiendo del ruido en los datos la estimación será cercana a los parámetros reales del modelo. Pregunta para el lector ¿Qué ocurre en el caso de outliers extremos? ¿Cómo lidiar con estos casos?
PDDL: Planning Domain Definition Language
PDDL es un lenguaje estandarizado desarrollado para agentes que resuelven problemas de planificación. El lenguaje es flexible y tiene los siguientes requerimientos:
-
Definir el dominio del problema
- Los predicados: van a ser estados que puedene ser verdaderos o falsos. Por ejemplo
in x,visited x,connected x y - Acciones: Las acciones tienen pre-requisitos y efectos. Por ejemplo si el agente se encuentra en la posición
a(in a),aestá conectado con b,connected a b, se puede tener la acciónmove x ycuyo efecto sea:in y,visited yy removerin a(hacer este predicado falso) - Cada acción puede tener un costo asociado.
- Los predicados: van a ser estados que puedene ser verdaderos o falsos. Por ejemplo
-
Tener una instancia del problema, para la cual se haga el plan.
Supongamos que tenemos un mapa de ciudades, y queremos recorrer todas las ciudades en el mínimo de tiempo posible hasta volver al punto inicial.

Fig 12: Ejemplo de mapa de ciudades.
En este caso, en PDDL el dominio sería:
(define (domain tsp-strips)
(:requirements :strips)
(:predicates (in ?x) (visited ?x) (not-visited ?x)
(starting ?x) (complete) (not-complete)
(connected ?x ?y))
(:action go-along
:parameters (?x ?y)
:precondition (and (in ?x) (not-visited ?y) (not-complete)
(connected ?x ?y))
:effect (and (not (in ?x)) (in ?y) (visited ?y) (not (not-visited ?y))))
(:action return-along
:parameters (?x ?y)
:precondition (and (in ?x) (starting ?y) (not-complete)
(connected ?x ?y))
:effect (and (not (in ?x)) (in ?y) (not (not-complete)) (complete)))
)
Ahora definamos la instancia en PDDL:
(define (problem ten-cities)
(:domain tsp-strips)
(:objects c1 c2 c3 c4 c5 c6 c7 c8 c9 c10)
(:init (connected c1 c2) (connected c1 c3) (connected c2 c4)
(connected c2 c5) (connected c3 c6) (connected c3 c7)
(connected c4 c8) (connected c4 c9) (connected c5 c10)
(connected c5 c1) (connected c6 c2) (connected c6 c3)
(connected c7 c4) (connected c7 c5) (connected c8 c6)
(connected c8 c7) (connected c9 c8) (connected c10 c1)
(visited c1) (not-visited c2) (not-visited c3)
(not-visited c4) (not-visited c5) (not-visited c6)
(not-visited c7) (not-visited c8) (not-visited c9)
(not-visited c10)
(in c1) (starting c1) (not-complete))
(:goal (and (visited c1) (visited c2) (visited c3) (visited c4)
(visited c5) (visited c6) (visited c7) (visited c8)
(visited c9) (visited c10) (complete)))
)
El plan retornado por un planner por ejemplo sería el mostrado en la figura 13.
(go-along c1 c2)
(go-along c2 c4)
(go-along c4 c9)
(go-along c9 c8)
(go-along c8 c6)
(go-along c6 c3)
(go-along c3 c7)
(go-along c7 c5)
(go-along c5 c10)
(return-along c10 c1)

Fig 13: Ejemplo de búsqueda de parámetros por mínimos cuadrados.
¿Agentes LLM?
Con los LLM y las nuevas tendencias en la industria, sale el concepto de agentes con LLMs. Estos agentes funcionan en un dominio abierto y son capaces de generar un plan como una consulta en lenguaje natural. Existen frameworks para connectar LLMs como LangChain.
Ahora ¿Qué solución es mejor? Depende del problema, requerimientos, conocimiento de expertos del dominio y coste dispuesto a pagar (no es barato hacer inferencias con LLM dependiendo de las queries a considerar, por ejemplo QPS).
Reflexiones
- Se pueden clasificar distintos tipos de agentes dependiendo de la “inteligencia” de estos. La inteligencia en este caso es una definición simplista que denota el nivel sofisticación del agente
- Todos los enfoques pueden reducirse a un problema de búsqueda. La estrategia cambia, y escoger cuál utilizar dependerá del problema a resolver.
- Existen lenguajes estandarizados para definir dominios y agentes.
- Las nuevas tendencias utilizan agentes que utilizan LLMs para el razonamiento y construcción de un plan. La “mejor” solución dependerá de las restricciones del problema.
Espero que el artículo haya sido interesante 😊. ¡Abrazos!